fiboa: Core Specification & Extensions
Last week, we introduced fiboa, a collaborative project with the Taylor Geospatial Engine (TGE) designed to standardize farm field boundary data and bootstrap an ‘architecture of participation’ around agricultural and related data. The center of fiboa is a specification for representing field boundary data in GeoJSON & GeoParquet in a standard way, with optional ‘extensions’ that specify additional attributes. But we believe that thinking of fiboa as ‘just’ a specification is outdated. fiboa is the entire ecosystem of data adhering to the specification, tools to help convert data (including using AI models to in turn create more data), the discussions and conversations that evolve the specs, and of course the community people who are building it all together.
This blog post dives into the heart of fiboa: the core specification and its extensions. We’ll explore the core attributes that define this format and how the extensions enable interoperability of all types of information that can be associated with a field boundary. You should start with the Introducing fiboa post if you’ve not read it, as it articulates the overall philosophy behind the project. This post goes deep into the specification & extensions, and then we’ll follow up with the current state of tools, data, and community.
Core specification
The core of fiboa is quite simple: it is a set of definitions for attribute names and values. One clear example is area. It’s quite common for geospatial files representing field boundaries to have a column for the area of the field, but it’s often called different things: area, area_ha, totalArea, etc. And even if it’s called the same thing the actual data definition could be different: area could easily be in acres or hectares, or even something else. So what fiboa does is picks a definition; in our case area is in hectares and must be a ‘float’ between 0 and 100,000. Any data that implements fiboa and successfully validates can then be definitively interpreted as being in hectares.
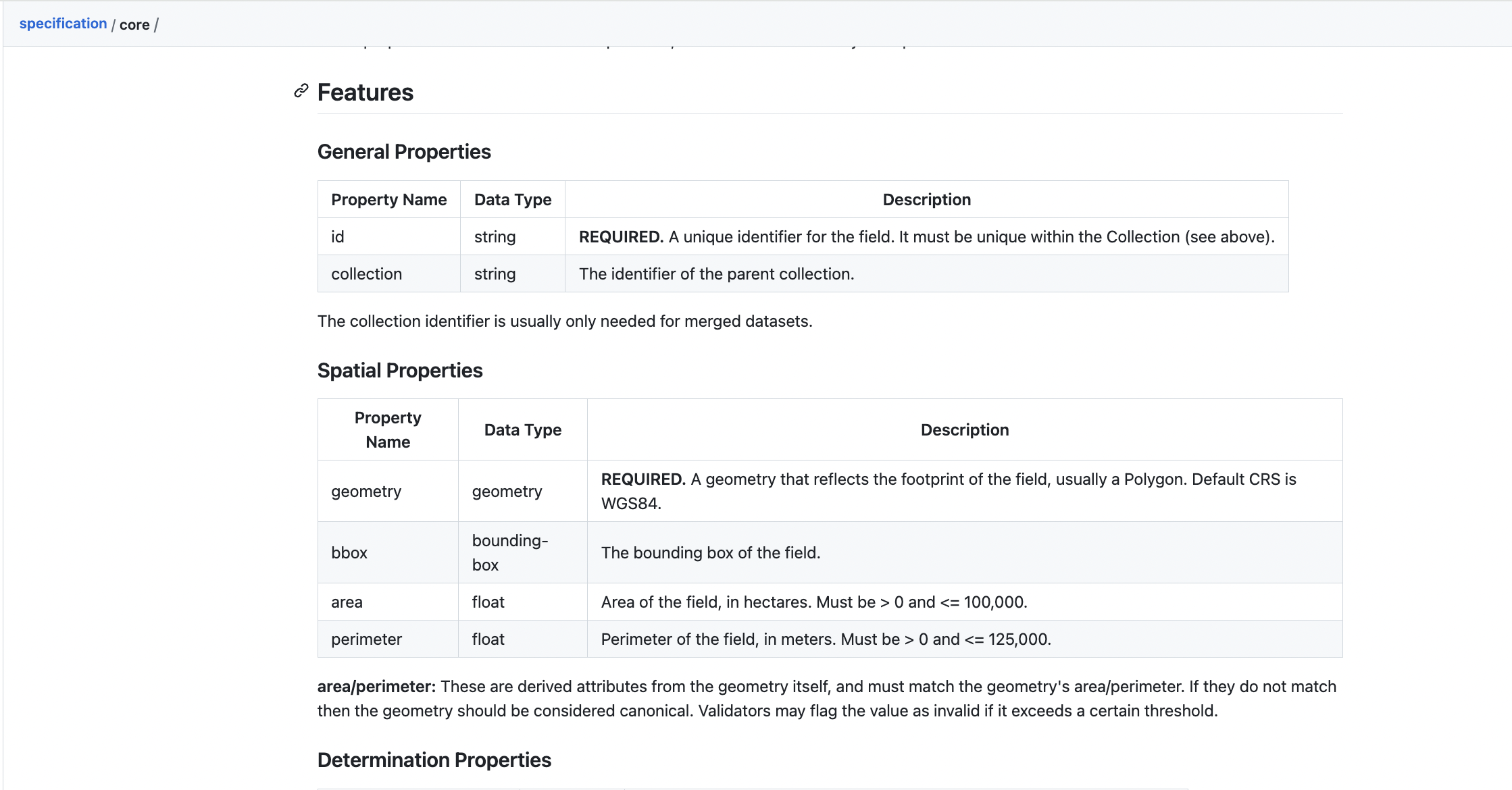
fiboa Core Spec, at github.com/fiboa/specification/tree/main/core
fiboa specifies the attributes in a human-readable form as shown above, along with a machine-readable yaml file. Then there are folders for GeoParquet and GeoJSON outputs that contain official examples and specs. This means that there are validation tools that can take any data in those formats and report whether it properly implements the core fiboa data schema (along with any extensions - more on those soon).
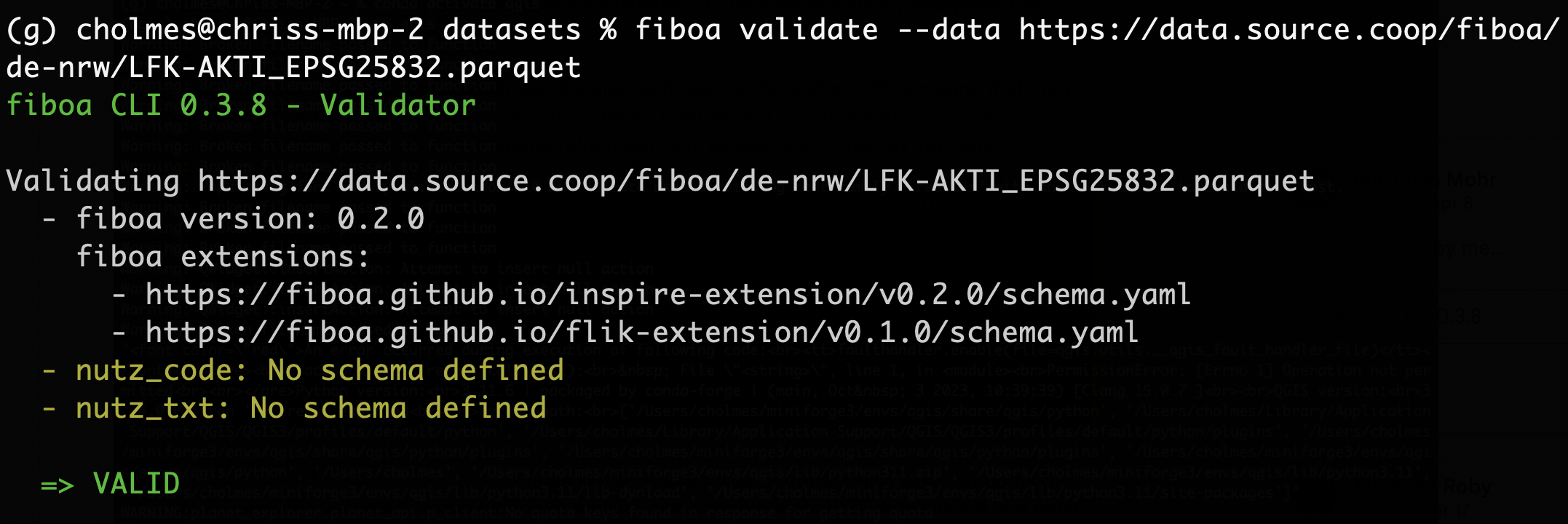
Validation of Field Boundaries for North Rhine-Westphalia (NRW), Germany using the fiboa CLI
GeoJSON generally works best for things like API responses or transferring small amounts of data. GeoParquet shines when storing or moving any sizable amount of data since it is a much faster and more compact format. GeoParquet is a newer format and there is not yet universal tool support, but a big benefit is it can be stored on the cloud and clients can easily stream just the bits they need. Major data projects like Overture Maps are supporting it and the ecosystem is growing fast, so we decided to embrace it as we envision all global fields represented in fiboa, and billions of polygons are much better served by a more modern cloud-native geospatial format. For the TGE Field Boundary Initiative, we’re using Source Cooperative as our primary data infrastructure, and it works great with GeoParquet.
Thankfully it is quite easy to transform any fiboa data into other geospatial formats like GeoPackage or Flatgeobuf, as the attribute names and values will be retained. We do not recommend using Shapefile due to various technical limitations of the format. Unofficial validators may emerge for those, or we could consider officially supporting them - we just wanted to start with a small core.
The number of attributes in the core is quite small, and that’s by design. The idea is that most all the ‘interesting’ data about the field will be in extensions. So even something that many people would consider a core property like ‘crop classification’ will go in extensions. This is so that the definitions can evolve more easily, and so we don’t have people who don’t adopt fiboa because they have their own crop classification system that works better for their use case. The extensions give the possibility of several crop classification extensions. Practically we do hope that one main crop classification extension emerges, and that will likely happen if the largest, most valuable datasets all use the same extension. But we don’t believe the small group of people involved at the start can get all the core attributes completely right from the start. Indeed we don’t even believe that there is one ‘true’ answer to the right data schema for agricultural data. So our approach is to create the tools for everyone to define what they need and to then validate against their own extensions. Naturally, some frequently used ‘core extensions’ will emerge. Much of the inspiration for this comes from the STAC specification. For STAC, several well-used extensions have emerged, and therefore we expect the same for fiboa.
As of right now, the only required attributes in the core fiboa specification are id and geometry. Then we have optional attributes for spatial properties (bbox, area, and perimeter), and a couple of properties about the creation (determination_method and determination_datetime).
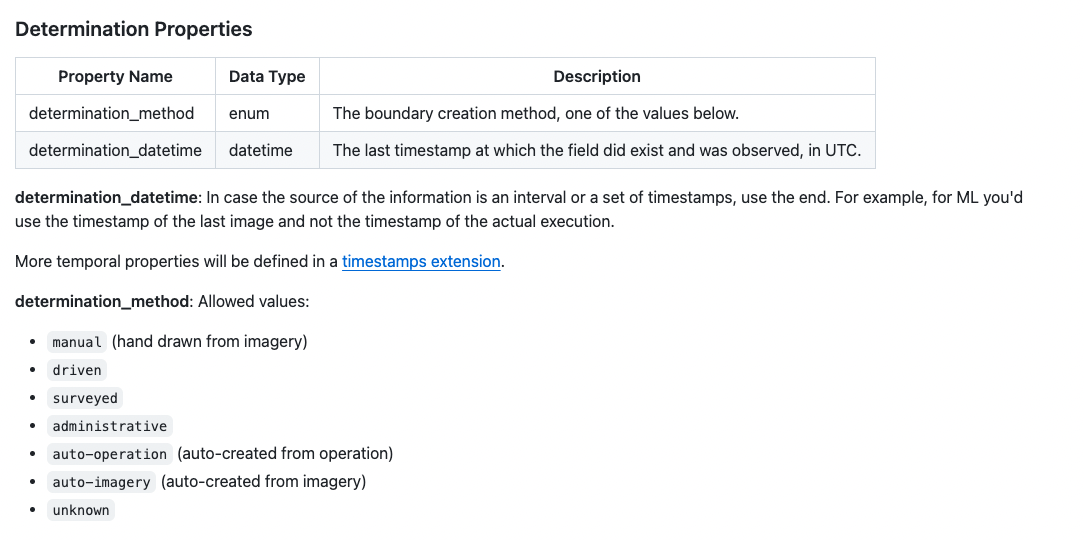
The method used to create the boundary is quite important, particularly in AI use cases where you would not want to train an AI on data that itself was auto-created by AI from other imagery. The determination_datetime was the subject of much debate, and we did talk through various datetimes that people care about a lot but decided that it’d be best to cover all the various datetime options in an extension that is explicit about what each time means. We did want to have one date time in the core and coalesced on the determination_datetime, which is the last time at which this particular field was observed, so you can tell if a field is up to date or created a while ago. We thought about making the datetime attribute required but did not want to end up with a bunch of bad time data as many datasets don’t have precise time information and they’d just end up dumping ‘something’ in there.
The core will likely evolve a good bit, and feedback on these decisions is more than welcome, as this release mostly aims to start the conversation. When we feel it’s more settled we’ll likely call it ‘beta’, but there are still some big things to figure out, like what should be at the ‘collection’ level and what to do when different collections of data are merged.
Extensions
I touched on the philosophy behind extensions above, and it’s hopefully clear that extensions in fiboa aren’t just extraneous information that doesn’t really matter. The bulk of fiboa’s value will be in extensions. There will likely be lots of different types of extensions: some that are generally accepted as the main way to do things in fiboa and widely understood by tools and others that are very niche and not widely used but valuable to a small number of users (e.g. an extension specific to a company or organization to help them better validate their data).
Implementing an extension enables the dataset to make use of the ecosystem of fiboa tools, including validations to ensure that the values in a dataset meet the requirements of an extension. This, in turn, lets tools ‘know’ that a particular value in two different datasets means the exact same thing and can be combined. This should lead to much more innovation in tools to work with the data since tool providers don’t need to code against particular datasets or try to get everyone to convert their data into a random schema for the tool to work. Everyone can work towards a common target, creating a virtuous cycle where converting agricultural data to fiboa makes it work with more tools, more tools get created because there’s more data in fiboa, and then more data gets converted because there are even more tools that come from converting data.
We put in quite a bit of work to make the process of creating extensions as easy as possible (and by ‘we’ I mean Matthias Mohr did a ton of awesome work, funded by TGE). Each extension is defined by a GitHub repository that contains all the information about the extension and publishes the schemas that tools directly call for validation. The cool thing is that Matthias created a ‘template’ where all you need to do is hit ‘use template’ and you’re 80% of the way to making an extension.
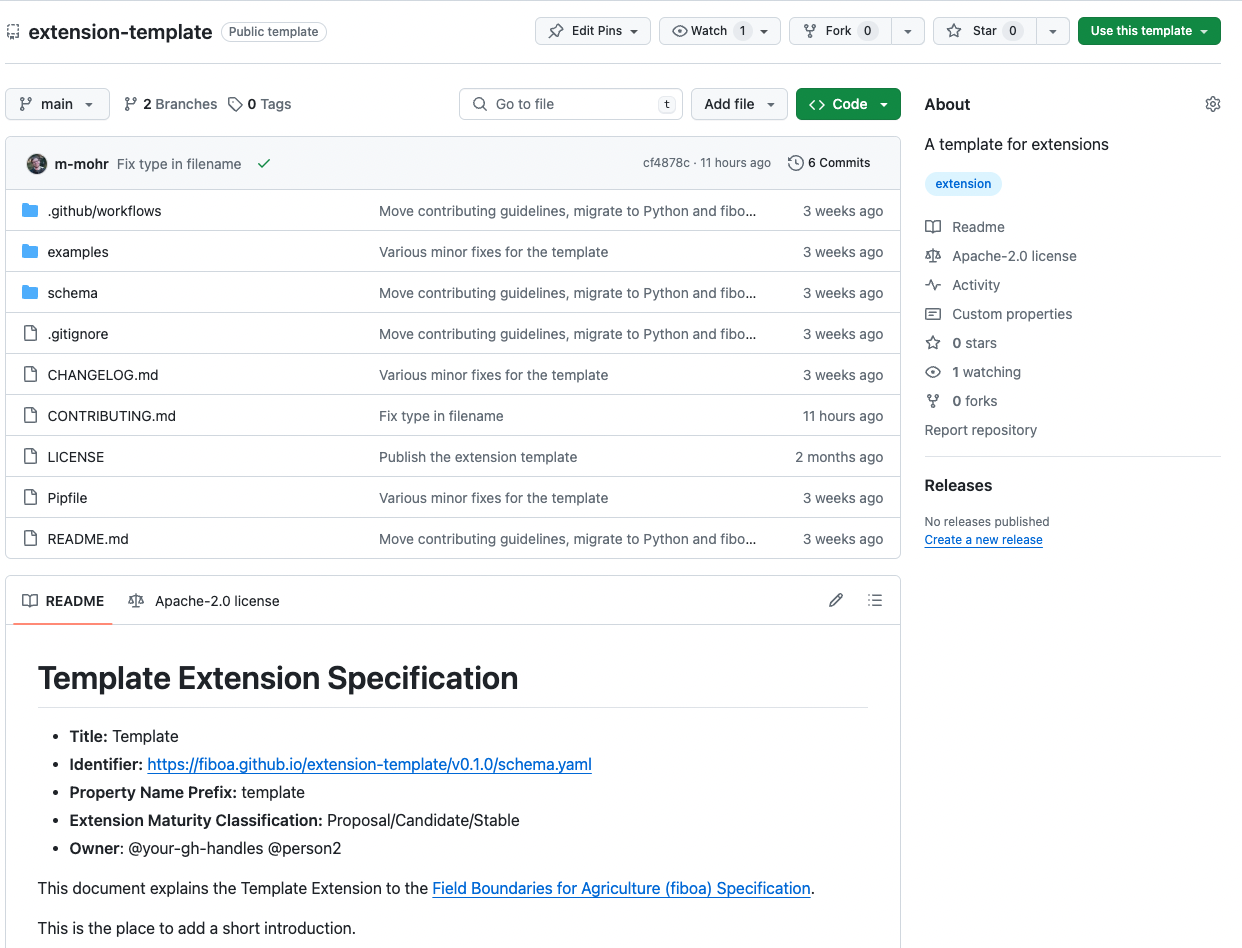
You edit the readme, customize a YAML template, and create an example GeoJSON file. Then, the repo template provides all the tools to convert it to GeoParquet, validate everything, and run continuous integration to ensure each new commit remains valid. When you hit ‘release’ for the repo, the schema is automatically published and any of the ecosystem tools can instantly start validating datasets against it. This was awesome to see in action at the initial workshop, as I was able to fully release a new extension and then validate data against it using the command-line tool in just a couple of hours.
Matthias has built a tutorial on creating a new extension, for anyone interested in trying to create one. You can find it at github.com/fiboa/tutorials/tree/main/create-extension, and it has a link to the video recording there as well.
Initial Extensions
So far we’ve only managed to create four extensions, but we aim for many more over the next few months. The one that saw a lot of effort during the workshop was the AI Ecosystem Extension.
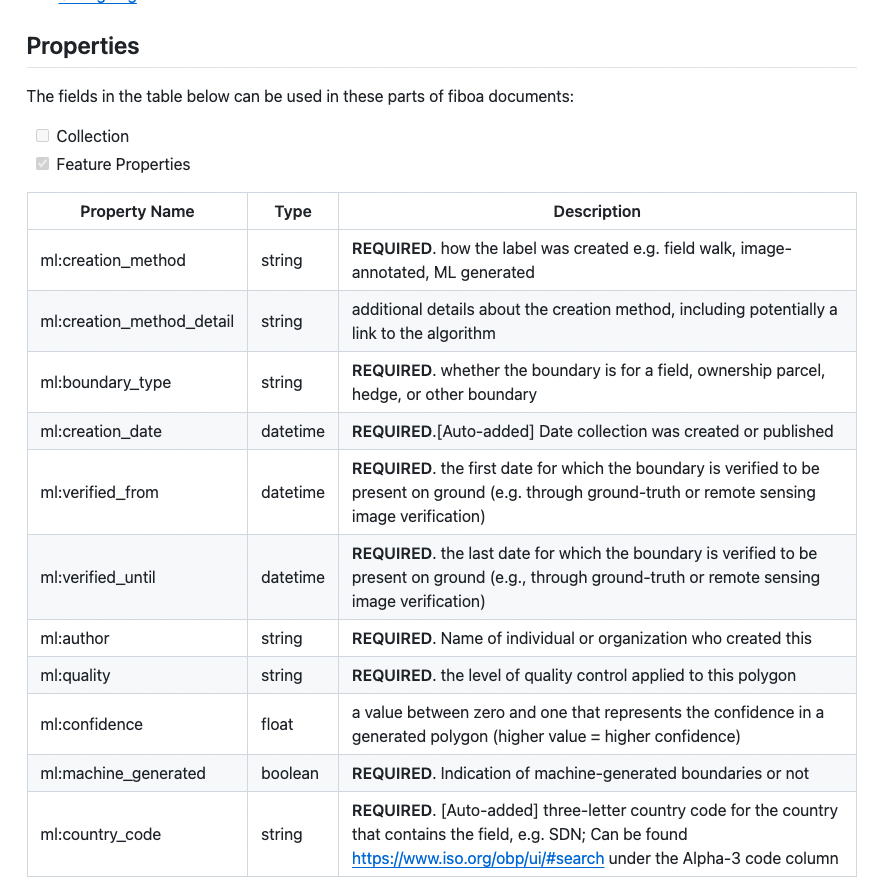
It includes everything you’d want in a dataset to be able to reliable machine learning from it, including things like the author, the quality, the confidence, and whether it was machine-generated. In time some of these things may migrate to more general extensions, but the idea was to first get down everything that an AI/ML tool would need to be able to use the fiboa dataset and run models with it. There was also work done in the workshop so GeoTorch could easily read in the data.
The other extension made in the workshop is the Tillage Extension. I worked with Jason Riopel of Bayer and Katie Murphy of the Donald Danforth Plant Science Center on this one. We started it as a ‘management practices’ extension but quickly realized that there were several attributes about tillage that people would use, so we broke it out into its own extension. I knew close to nothing about tillage, so it was cool to have them brainstorm what people want to know, what to call the attributes, and how to explain them. The extension is by no means ‘done’, but we managed to put out a 0.1 release. The next step will be to try to get one or more ‘real’ datasets converted, to validate that it works with existing data.
The INSPIRE and FLIK extensions define specific identifiers that are commonly used in the EU and Germany. Those two were added to support some of the first datasets converted to fiboa and hosted on Source Cooperative. I think that will be one of the main ways extensions get developed - start with a dataset to be converted and look at the attributes that aren’t already in fiboa. And then figure out if some of them are really ‘common’ ones that many datasets would want to represent. It’s worth doing some looking at other datasets, but since making an extension is so easy it’s also great to just create the extension and then solicit feedback as others hit similar problems, and evolve it in the open.
Next Extensions
While each extension gets an individual repository, we also have an overall Extensions Repository at github.com/fiboa/extensions that lists all available extensions. The issues in the extensions repository serve as a tracker for potential new extensions. Right now we’ve only got three extensions listed as priorities, but the workshop generated many more ideas that we’ll post to the tracker soon. Some examples include yield, crop classification, soil moisture, phenology, irrigation, soil information, climate risk, harvest dates, deforestation, ownership information, surface temperature, etc.
Two proposed extensions that are pretty critical to get to soon are Identifiers and Timestamps. For IDs, we are particularly interested in things like Varda’s Global FieldID being represented easily, to help promote their awesome work. We know that many other ID schemes are important to people, so creating an extension to allow for those to exist within fiboa is a priority. For Timestamps, we anticipate a deep discussion of all the different types of time that people care about with fields. We started talking about it at the workshop, and it became clear it was a much bigger topic than we could handle in an hour or two. We also ticketed ‘management practices’, which will likely be broken into multiple extensions on cover crop, fertility, crop protection, manure, irrigation, residue management, etc. It may make sense to have an overarching extension that groups them together.
Extensions are generally the area that is ripest for collaboration, and we’re keen to get at least some initial alpha releases out. The recommended way to work on these is to start with one dataset that represents some additional data related to field boundaries and see how they do it. Ideally, at least a couple of datasets that represent the same attributes are found, and if they all do things similarly then it should be easy to determine what goes in the extension. If their approach differs, just pick the one that makes the most sense and is the most future-proof. The idea is to release ‘early and often’, and to get feedback through actually ‘doing’, not trying to gather all potential stakeholders in a room. Ideally, by a ‘1.0 release’ of any extension there are many different datasets in fiboa that use the extension, so we feel confident that it works well.
Next Steps
So I hope this post served as a solid introduction to the core fiboa specifications. We’ll aim to follow-up very soon with details on the data, tools and community that are just as important as the core spec. And after that we’ll post more of the ‘why’ behind the initiative. If you’re intrigued by what you’ve read then please consider joining us! We certainly can’t do it all alone, and this movement is only going to succeed beyond our dreams if we manage to attract far more people than the original group. We’ve got a lot of great momentum, and the amazing support of Taylor Geospatial Engine, but the goal is to use these next months to really bootstrap the community that will live beyond the initial Innovation Bridge Initiative.
To join the community check out our developer communication channels or just start digging into all the repos linked to from github.com/fiboa.
Our blog is open source. You can suggest edits on GitHub.